Modelling Label Dependencies for Multi-label Text Classification
exploring bi-directional multiple relations between labels
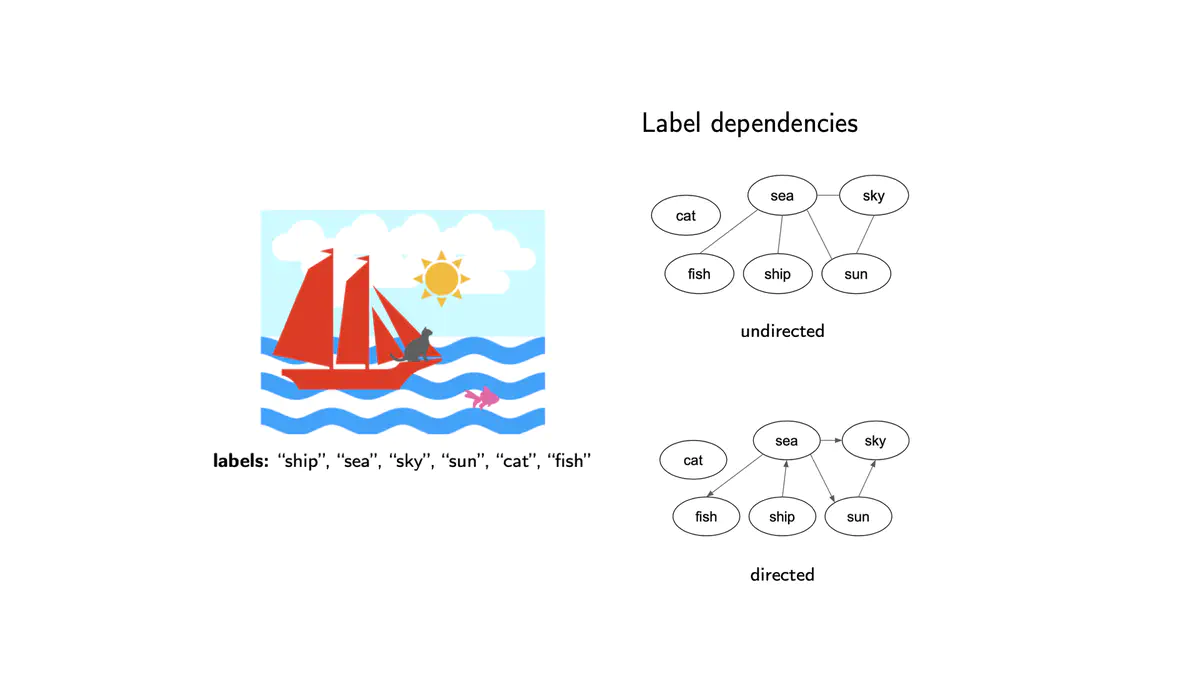
Multi-label Classification (MLC)
As the name implies, multi-label classification entails selecting the correct subset of tags for each instance. Its main difference from multi-class learning is that the class values are not mutually exclusive in multi-label learning and usually no prior dependencies between the labels is provided explicitly. In general, the existing literature treats the relationship between labels as co-occurrences in an undirected manner. Though, there are usually multiple types of dependencies between labels and their strength s, they are not independent from the direction of the specified edge. For instance, the “ship” and “sea” labels have an obvious dependency, but the presence of the former implies the latter much more strongly than vice versa. Between the effective methods that attempt to model label dependencies, message passing neural networks make use of the representative power of graphs, while recurrent neural network based approaches learn a prediction path. The prediction path concept enables focusing on the next probable label given the prediction implicitly and avoids irrelevant labels. The order in the path introduces a notion of direction for the dependencies. Our motivation to introduce relational graph neural networks, is to model label dependencies emerging from combining the advantage of these two lines of research.
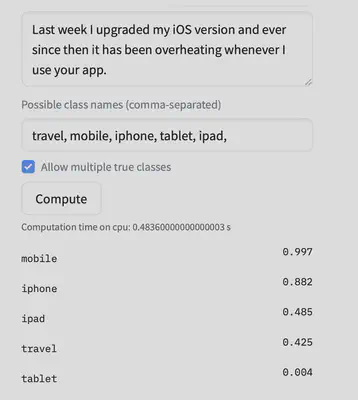
I would like to share an example with you to demonstrate how valuable different types of relationships can be to boost the prediction performance. Hugging Face is a PyTorch based natural language processing library, in which researchers can upload their pertained models and provide an application programming interface for them to be tried.
Here, I experiment with the most popular zero-shot learning model using a customer complain example. Based on the review we see that this is relevant with an apple product but it could be regarding either an iPhone or iPad. The predictions for iPhones and mobile tags are high but the predictions for iPads is only as high as the irrelevant tag of travel while the tag of tablet is predicted to be very low. Using the dependencies it could be inferred that most probable outcomes are irrelevant to travel and close to tablet, and using that information to update predictions could really boost the performance.
Multi-relation Message Passing for MLC (MrMP)

In our work MrMP, we consider two types of statistical relationships; pulling and pushing. In order to find prior adjacency matrices, we first test the existence of dependency for each label pair, and then decide whether that statistical dependency is of the pushing or pulling type.
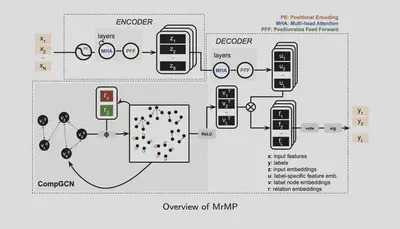
MrMP combines the idea of LaMP and CompGCN. The encoder initializes input word embeddings then stacks several layers of self-attention to construct the sequential representation of input. The decoder is composed of a label-relation module and a label-feature module. The label-relation module is responsible for capturing the multi-relational dependencies among labels. The label-feature module extracts the relevant features for each label. The label-relation module initializes the label node embeddings and stacks CompGCN layers.
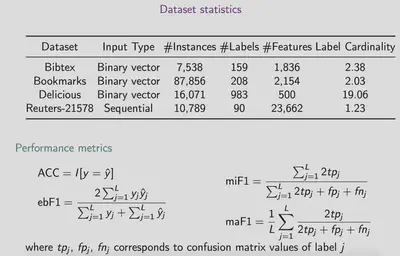
We use four benchmark datasets in text domain for which the number of labels range from 90-983. We use accuracy, example-based F1 score, micro-averaged and macro averaged F1 scores to evaluate our method.
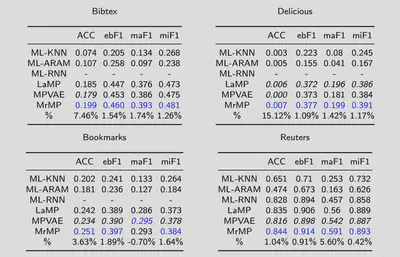
Overall our experiments show that MrMP obtains better performance than the state-of-art methods. The value of the multi-relation approach is most obvious in subset accuracy in which MrMP outperforms the baselines by 7% on average. The overall performance improvements for the F1 scores are below 2%. The maF1 improvement is slightly greater than the miF1 improvement. Comparatively, maF1 focuses more on rare labels; this is in line with the intuition that the guidance provided by incorporating multiple relations is more useful for rare labels.
References
[1] J. Lanchantin, A. Sekhon, and Y. Qi. Neural message passing for multi-label classification. In Proc. ECML-PKDD, volume 11907, pages 138–163, 2020.
[2] S. Vashishth, S. Sanyal, V. Nitin, and P. Talukdar. Composition-based multi-relational graph convolutional networks. In Proc. Int. Conf. Learning Rep., 2020.