Extreme Multi-label Classification
exploring various label relationships large scale multi-label datasets

Problem definition
Extreme multi-label text classification refers to the multi-label document classification problem in which the number of labels can reach to millions. The ones listed here are the most traditional datasets that are used to evaluate general purpose classifiers of the problem. In comparison with conventional multi-label classification, even the smallest extreme classification datasets are much larger in label space.
Literature
Summary
How to learn input text representations?
- BOW and variants: Parabel [9], Bonsai [2]
- Deep learning: XML-CNN [4], AttentionXML [12]
- Transfer learning: X-BERT [1], APLC-XLNet [11]
How to handle the large output space efficiently?
- One-vs-all
- Embedding based
- Tree-based: Parabel [9], Bonsai [2], AttentionXML [12]
- Deep learning: XML-CNN [4], AttentionXML [12], APLC-XLNet [11]
Details
We can investigate the literature based on how they address these two main design problems. In terms of learning text representation, the NLP community has developed various methods concerning all types of tasks such as machine translation, or question answering. Here we focus on the current practices on the document classification task.
The traditional approach is using bag-of-words. That is; representing each document by a vector of word frequencies within the document. These methods do not account for relative token positions thus failing to reveal the true contextual and semantic information. However, some state of the art methods are still making use of bag-of-word features due to its efficiency.
Various neural network architectures are proposed to generate input word embeddings from raw text during training for multi-label text classification. The pioneering work in this group is XML-CNN which employs convolutional neural networks. The most important method in this category is AttentionXML with leading prediction performance levels both on frequent and rare labels.
More recently, fine-tuning pre-trained NLP models to learn text representations is found to be useful both in terms of accuracy and computational efficiency. Examples so far are X- BERT and APLC-XLNet. The performance of APLC-XLNet is quite comparable to AttentionXML while it is much more efficient computation-wise.
The second categorization consists of the method used to represent label space. One-vs-all treats each label independently. Usually the resulting computational complexity is very hard to manage for XMLC if no efficiency techniques such as sparse learning is used.
Embedding based methods, implicitly account for label dependencies in the sense that the label space is compressed into lower dimensions using correlation levels. However, the loss of information during the compressing phase is difficult the recover.
In general, basic tree-based methods can be divided into two in terms of partitioning; as label-based and instance-base ones. Either instances or labels are partitioned into child nodes until a stopping criteria is satisfied such that same leaf node members are similar. The prediction on instance trees is made by the leaf node classifiers, on label tree is made by traversed node classifiers. Some of the most important state-of-the art methods fall under this category. Various deep leaning methods usually train an end-to-end network that learns input from raw text to avoid feature engineering. Since AttentionXML employs an ensemble of networks it can be considered in both category.
Problem Characteristics
Extreme multi-label text classification has a fabulous repository that I use as a starting point for getting to know aboout datasets and most important practices.
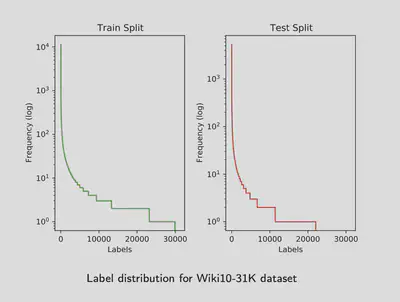
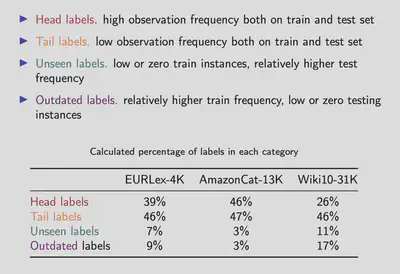
Head labels refer to the ones with high observation frequencies both on the train and test set, eventually they are each to learn and predict.
Tail labels refer to the ones with low observation frequencies both on the train and test set. They are usually more reflective on prediction accuracy than on head labels.
Unseen labels have low or zero train instances, but relatively higher test frequencies. These ones tend to appear mostly in time evolving datasets. For instance, web-site tagging datasets with enlarging label spaces by some user activity.
If the trend is opposite, then we name the labels outdates. I believe, investigating and treating labels based on their frequency behaviour may be critical while designing a classifier.
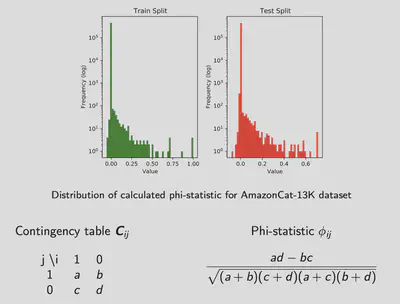
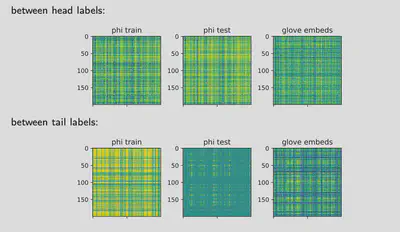
References
[1] W.-C. Chang, H.-F. Yu, K. Zhong, Y. Yang, and I. S. Dhillon. X-bert: Extreme multi-label text classification with using bidirectional encoder representations from transformers. In Proc. NeurIPS Science Meets Engineering of Deep Learning Workshop, 2019.
[2] S. Khandagale, H. Xiao, and R. Babbar. Bonsai - diverse and shallow trees for extreme multi-label classification. In arXiv preprint arXiv:1904.08249, 2019.
[3] J. Lanchantin, A. Sekhon, and Y. Qi. Neural message passing for multi-label classification. In Proc. ECML-PKDD, volume 11907, pages 138–163, 2020.
[4] J. Liu, W.-C. Chang, Y. Wu, and Y. Yang. Deep learning for extreme multi-label text classification. In Proc. Int. ACM SIGIR Conf. Research and Development in Information Retrieval, page 115–124, 2017.
[5] E. Loza Mencía and J. Fürnkranz. Efficient pairwise multilabel classification for large-scale problems in the legal domain. In Proc. European Conf. Machine Learning and Knowledge Discovery in Databases (ECML-PKDD), pages 50–65, 2008.
[6] J. McAuley and J. Leskovec. Hidden factors and hidden topics: understanding rating dimensions with review text. In Proc. ACM Conf. Recommender systems, 2013.
[7] M. Ozmen, H. Zhang, P. Wang, and M. Coates. Multi-relation message passing for multi-label text classification. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), submitted.
[8] J. Pennington, R. Socher, and C. D. Manning. Glove: Global vectors for word representation. In Proc. Conf. Empirical Methods in Natural Language Processing (EMNLP), 2014.
[9] Y. Prabhu, A. Kag, S. Harsola, R. Agrawal, and M. Varma. Parabel: Partitioned label trees for extreme classification with application to dynamic search advertising. In Proc. World Wide Web Conference, page 993–1002, 2018.
[10] S. Vashishth, S. Sanyal, V. Nitin, and P. Talukdar. Composition-based multi-relational graph convolutional networks. In Proc. Int. Conf. Learning Rep., 2020. URL https://openreview.net/forum?id=BylA_C4tPr.
[11] H. Ye, Z. Chen, D. Wang, and B. D. Davison. Pretrained generalized autoregressive model with adaptive probabilistic label clusters for extreme multi-label text classification. In Proc. Int. Conf. Machine Learning (ICML), 2020.
[12] R. You, Z. Zhang, Z. Wang, S. Dai, H. Mamitsuka, and S. Zhu. Attentionxml: Label tree-based attention-aware deep model for high-performance extreme multi-label text classification. In Proc. Adv. Neural Information Processing Systems (NeurIPS), 2019.
[13] A. Zubiaga. Enhancing navigation on wikipedia with social tags. In arXiv preprint arXiv:1202.5469, 2012, 2012.